서울시 CCTV 현황 분석
import pandas as pdpandas 모듈을 통해 SCV 파일과 엑셀 파일을 쉽게 읽을 수 있습니다.


CCTV_Seoul = pd.read_csv('c:/anaconda3/test/CCTV_in_Seoul.csv', encoding='utf-8')
CCTV_Seoul.head(4)경로에 실습 파일을 넣어주고 읽어줍니다.
판다스 모듈에서 CSV 파일을 읽어주는 명령어는 read_csv입니다.
한글 사용을 위해서 인코딩을 UTF-8로 설정해 줬습니다.
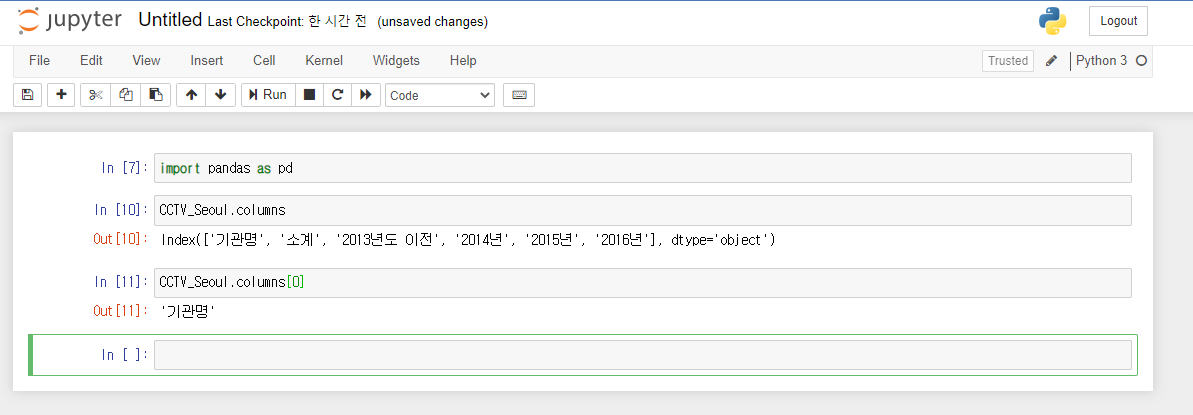
CCTV_Seoul.columns판다스 데이터는 제일 첫 줄에 보이는 것이 해당하는 열을 대표하는 일종의 제목이라고 합니다.
CCTV_Seoul.columns[0]제목 줄의 첫 번째 값을 반환할 수 있습니다.

CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0] : '구별'}, inplace=True)
CCTV_Seoul.head()기관명을 구별로 바꿔줬습니다.
이렇게 이름을 바꿔주는 명령어는 rename을 사용합니다.
inplace=True는 실제 CCTV_Seoul이라는 변수의 내용을 갱신하라는 의미입니다.

pop_Seoul = pd.read_excel('c:/anaconda3/test/population_in_Seoul.xls',
header = 2,
usecols = 'B, D, G, J, N',
encoding = 'utf-8')
pop_Seoul.head()엑셀 파일을 읽는 명령어는 read_excel입니다.
첫 세 줄이 열의 제목처럼 되어 있어서 세 번째 줄부터 읽으라고 header=2라는 옵션을 사용했습니다.
B, D, G, J, N 열만 읽도록 usecols= 'B, D, G, J, N' 옵션을 사용했습니다.

pop_Seoul.rename(columns={pop_Seoul.columns[0] : '구별',
pop_Seoul.columns[1] : '인구수',
pop_Seoul.columns[2] : '한국인',
pop_Seoul.columns[3] : '외국인',
pop_Seoul.columns[4] : '고령자'}, inplace=True)
pop_Seoul.head()컬럼 이름에 문제가 있다면 rename 명령어를 통해 컬럼의 이름을 변경할 수 있습니다.
이렇게 여러 컬럼의 이름을 한 번에 변경도 가능합니다.

CCTV_Seoul.head()pandas를 이용해서 CCTV와 인구현황 데이터를 파악할 수 있습니다.
우선 구별 CCTV 데이터를 조회합니다.

CCTV_Seoul.sort_values(by='소계', ascending=True).head(5)구별 CCTV 데이터에서 전체 개수인 소계로 정렬을 했습니다.
정렬된 내용을 통해 CCTV의 전체 개수가 가장 작은 수는 도봉구라는 것을 알 수 있습니다.

CCTV_Seoul.sort_values(by='소계', ascending=False).head(5)ascending를 False로 줘서 많은 순서대로 보여지도록 했습니다.
제일 많은 CCTV를 가지고 있는 구별은 강남구라는 것을 알 수 있습니다.

CCTV_Seoul['최근증가율'] = (CCTV_Seoul['2016년'] + CCTV_Seoul['2015년'] + \
CCTV_Seoul['2014년']) / CCTV_Seoul['2013년도 이전'] * 100
CCTV_Seoul.sort_values(by='최근증가율', ascending=False).head(5)2014년부텅 2016년까지 최근 3년간 CCTV를 더하고 2013년 이전 CCTV 수로 나눠서 최근 3년간 CCTV 증가율을 계산했습니다.
최근 3년간 CCTV가 많이 증가한 구는 종로구인 것을 알 수 있습니다.

pop_Seoul.head()pop_Seoul 변수를 확인해 봤는데 0번 행에 합계가 보입니다.

pop_Seoul.drop([0], inplace=True)
pop_Seoul.head()서울시 전체 합계를 drop 명령어를 통해 지웠습니다.

pop_Seoul['구별'].unique()구별 컬럼의 unique를 조사했습니다.
유니크 조사는 반복된 데이터는 하나로 나타나서 한 번이상 나타난 데이터를 확인해 줍니다.

pop_Seoul['외국인비율'] = pop_Seoul['외국인'] / pop_Seoul['인구수'] * 100
pop_Seoul['고령자비율'] = pop_Seoul['고령자'] / pop_Seoul['인구수'] * 100
pop_Seoul.head()각 구별 전체 인구를 이용해서 구별 '외국인비율'과 '고령자비율'을 계산했습니다.

pop_Seoul.sort_values(by='인구수', ascending=False).head(5)인구수로 정렬했습니다.
인구수가 제일 많은 구는 송파구인 것을 알 수 있습니다.
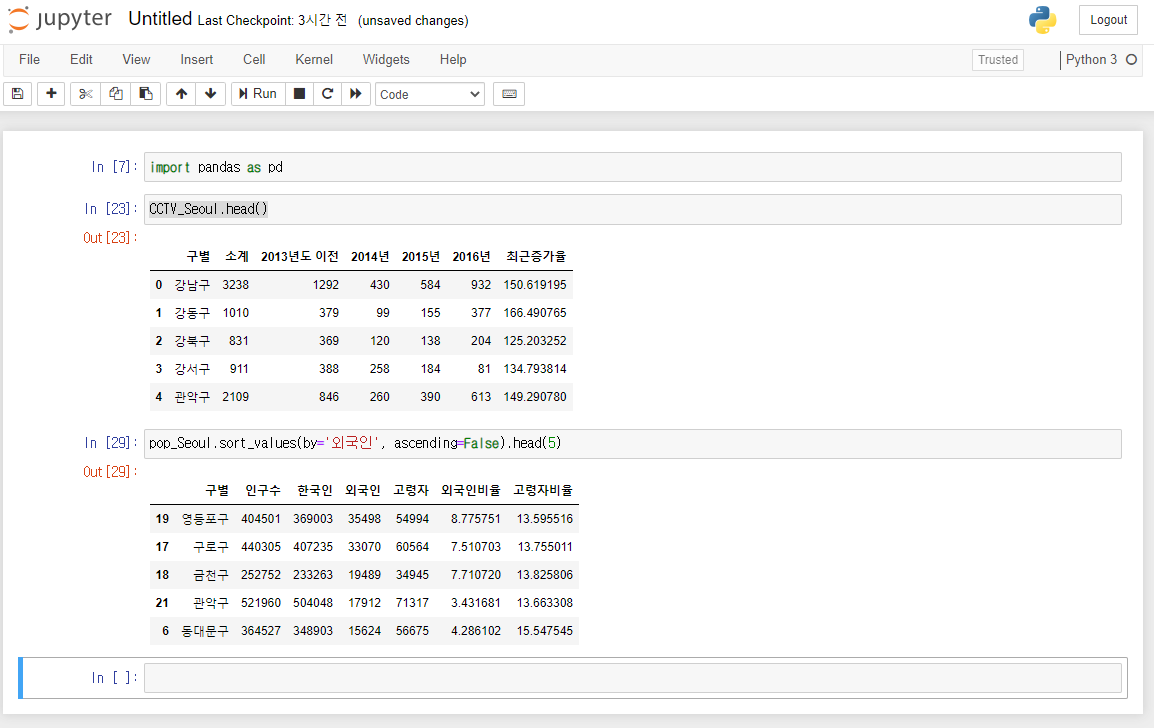
pop_Seoul.sort_values(by='외국인', ascending=False).head(5)외국인 인구수도 위와 같은 방법으로 알아볼 수 있습니다.
외국인은 영등포구에 가장 많이 있습니다.

pop_Seoul.sort_values(by='외국인비율', ascending=False).head(5)외국인 비율을 알아봤습니다.
외국인 숫자가 아닌 비율 또한 영등포구가 가장 높은 것을 알 수 있습니다.

pop_Seoul.sort_values(by='고령자', ascending=False).head(5)고령자가 많은 곳은 송파구입니다.

pop_Seoul.sort_values(by='고령자비율', ascending=False).head(5)고령자 숫자가 아닌 비율이 높은 곳은 강북구입니다.

data_result = pd.merge(CCTV_Seoul, pop_Seoul, on='구별')
data_result.head()merge 명령으로 두 데이터의 공통된 컬럼인 '구별'로 merge할 수 있습니다.

del data_result['2013년도 이전']
del data_result['2014년']
del data_result['2015년']
del data_result['2016년']
data_result.head()컬럼을 지우는 명령어입니다.
행 방향으로 삭제하는 것은 drop이고 열을 삭제하는 명령어는 del입니다.

data_result.set_index('구별', inplace=True)
data_result.head()그래프를 그릴 것을 생각하면 index는 구별로 하는 게 편합니다.
index를 설정하는 명령어가 set_index 명령어 입니다.

np.corrcoef(data_result['고령자비율'], data_result['소계'])
np.corrcoef(data_result['외국인비율'], data_result['소계'])
np.corrcoef(data_result['인구수'], data_result['소계'])상관 계수를 계산하는 명령이 numpy에 있는 corrcoef 명령입니다.
이 명령의 결과는 행렬로 나타납니다.
CCTV 개수는 고령자비율, 외국인비율과는 관계가 없습니다.

data_result.sort_values(by='소계', ascending=False).head(5)
data_result.sort_values(by='인구수', ascending=False).head(5)CCTV 개수와 인구수는 약한 상관계수로 조금 더 들여다 봅니다.
CCTV 현황 그래프로 분석하기
matplotlib이 기본적으로 가진 폰트는 한글을 지원하지 않습니다.
때문에 matplotlib의 폰트를 변경할 필요가 있습니다.
PC의 운영체제가 맥 OS나 윈도우 모두 배려합니다.

data_result.head()CCTV 데이터와 인구 현황 데이터가 merge된 결과 변수 data_result를 확인합니다.

import platform
from matplotlib import font_manager, rc
plt.rcParams['axes.unicode_minus'] = False
if platform.system() =='Darwin':
rc('font', family='AppleGothic')
elif platform.system() == 'Windows':
path = "c:/Windows/Fonts/malgun.ttf"
font_name = font_manager.FontProperties(fname=path).get_name()
rc('font', family=font_name)
else:
print('Unknown system .. sorry ~ ~ ')matplotlib이 기본적으로 가진 폰트는 한글을 지원하지 않기 때문에 matplotlib의 폰트를 변경할 필요가 없습니다.

plt.figure()
data_result['소계'].plot(kind='barh', grid=True, figsize=(10,10))
plt.show()pandas 데이터 뒤에 plot 명령어를 붙여주면 바로 그려줍니다.
kind = 'barh'로 지정해서 수평바(bar)로 그리도록 합니다.
grid = True로 grid를 그리고 figsize로 그림 크기도 지정해 줍니다.

data_result['소계'].sort_values().plot(kind='barh', grid=True, figsize=(10,10))
plt.show()위에 수평바 그래프를 정렬해서 봅니다.
한 눈에 볼 수 있어 좋습니다.
CCTV 개수는 강남구가 월등히 많은 것을 확인할 수 있습니다.

data_result['CCTV비율'] = data_result['소계'] / data_result['인구수'] * 100
data_result['CCTV비율'].sort_values().plot(kind='barh', grid=True, figsize=(10,10))
plt.show()인구 대비 CCTV 비율을 계산해서 정렬합니다.
인구 대비 CCTV를 보면 종로와 용산이 많고 송파는 인구대비 CCTV가 적은 것을 볼 수 있습니다.

plt.figure(figsize=(6,6))
plt.scatter(data_result['인구수'], data_result['소계'], s = 50)
plt.xlabel('인구수')
plt.ylabel('CCTV')
plt.grid()
plt.show()scatter 함수를 사용해 s = 50로 마커의 크기를 잡고 그립니다.
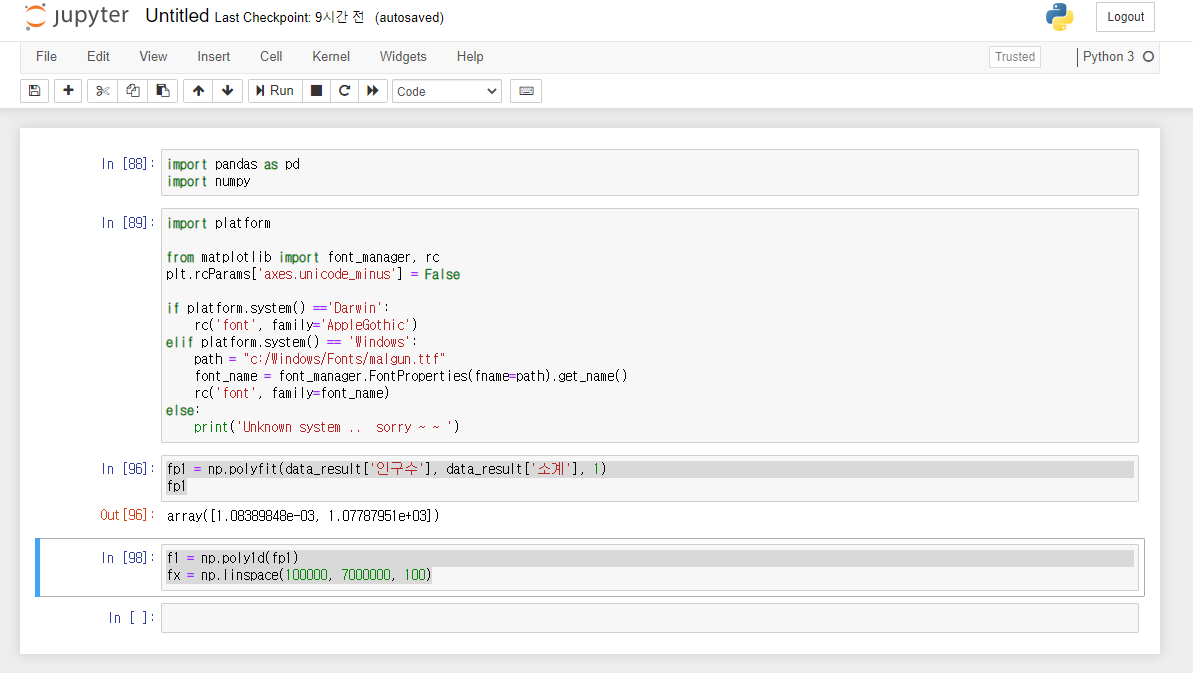
fp1 = np.polyfit(data_result['인구수'], data_result['소계'], 1)
fp1f1 = np.poly1d(fp1)
fx = np.linspace(100000, 7000000, 100)데이터를 대표하는 직선을 그립니다.
numpy의 polyfit 명령으로 직선을 만들어 줍니다.
이를 위해 x축과 y축의 데이터를 얻어야 하는데 x축 데이터는 numpy의 linespace로 만들고, y축은 poly1d로 만듭니다.

plt.figure(figsize=(10,10))
plt.scatter(data_result['인구수'], data_result['소계'], s=50)
plt.plot(fx, f1(fx), ls='dashed', lw=3, color='g')
plt.xlabel('인구수')
plt.ylabel('CCTV')
plt.grid()
plt.show()직선이 데이터의 대표값 역할을 합니다.
인구수가 300,000일 때는 CCTV는 1,400 정도여야 합니다.
'프로그래밍언어 > Python' 카테고리의 다른 글
| [Python] : [파이썬 머신러닝 실무 테크닉 100] : 데이터를 모두 로딩하자 (0) | 2021.12.23 |
|---|---|
| [Python] : [파이썬 머신러닝 실무 테크닉 100] : 머신러닝 공부를 시작한다. (0) | 2021.12.23 |
| [Python] : Pandas, 판다스 기초(1부) (0) | 2021.11.24 |
| [Python] : Jupyter notebook, 주피터 노트북 설치 (0) | 2021.11.24 |
| [Python] : Anaconda, 아나콘다 설치 (0) | 2021.11.24 |



댓글