반응형
하둡분산파일시스템에 저장된 데이터는 압축하여 저장이 가능하다.
맵리듀스 처리를 효율적으로 하기 위해 시퀀스 파일로 생성한다.
분석 및 처리의 빈도수 높지 않는 파일은 압축하여 저장하면, 하둡분산파일시스템의 저장소 양은 확보된다.
압축에 사용되는 압축 알고리즘은 SnappyCodec를 활용
- SnappyCodec
- 맵리듀스 분석 대상 및 결과에 대한 압축을 위해 개발된 압축 방식
- 하둡에서만 사용 가능
- Gzip과 유사한 압축 알고리즘 사용
- 다른 압축 알고리즘에 비해 상당히 빠른 압축 및 해제 시간을 가짐
- 블럭 단위 압축을 위해 사용
- 블럭 단위 압축을 하는 이유
- 압축 방법은 라인별 압축을 수행하는 ‘레코드단위 방식’일정 레코드를 묶어 ‘블록별 압축하는 블록단위’로 구분된다.
- 압축 효율성은 블록단위에 비해 레코드단위 방식이 약 5%이상 좋다.
- 그러나 압축 및 압축 해제 속도면에 블록단위 방식이 월등하기 때문에 블록단위 방식을 사용한다.
드라이버 파일만 작성한다.
기본 Map 함수를 활용해 기존 파일의 변환 처리만 수행한다.
package hadoop.MapReduce.seq;
import lombok.extern.log4j.Log4j;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.compress.SnappyCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
@Log4j
public class CreateCompressSequenceFile extends Configuration implements Tool {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.exit(-1);
}
int exitCode = ToolRunner.run(new CreateCompressSequenceFile(), args);
System.exit(exitCode);
}
@Override
public void setConf(Configuration conf) {
// App 이름 정의
conf.set("AppName", "Compress Sequence File Create Test");
}
@Override
public Configuration getConf() {
//맵리듀스 전체에 적용될 변수를 정의할 때 사용
Configuration conf = new Configuration();
//변수 정의
this.setConf(conf);
return conf;
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = this.getConf();
String appName = conf.get("AppName");
System.out.println("appName = " + appName);
// 맵리듀스 시랳ㅇ을 위한 잡 객체를 가져온다.
// 하둡이 실행되면, 기본적으로 잡 객체를 메모리에 올린다.
Job job = Job.getInstance(conf);
// 맵리듀스 잡이 시작되는 main 함수가 존재하는 파일 설정
job.setJarByClass(CreateCompressSequenceFile.class);
// 맵리듀스 잡 이름 설정, 리소스 매니저 등 맵리듀스 실행 결과 및 로그 확인할 때 편리
job.setJobName(appName);
// 분석할 폴더(파일) -- 첫 번째 파라미터
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 분석 결과가 저장되는 폴더(파일) -- 두 번째 파라미터
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 시퀀스 파일 구조 변환하기
job.setOutputFormatClass(SequenceFileOutputFormat.class);
// 생성될 파일에 압축을 진행할지 설정(true:압축수행)
FileOutputFormat.setCompressOutput(job, true);
// 생성될 파일을 압축할 때 사용할 알고리즘 선택(SnappyCodec 사용)
FileOutputFormat.setOutputCompressorClass(job, SnappyCodec.class);
// 압축 방식 설정(BLOCK마다 압축, RECORD: 한 줄마다 압축)
SequenceFileOutputFormat.setOutputCompressionType(job, SequenceFile.CompressionType.BLOCK);
// 리듀서 객체를 생성하지 못 하도록 객체의 수를 0 으로 정의
job.setNumReduceTasks(0);
// 맵리듀스 실행
boolean success = job.waitForCompletion(true);
return (success ? 0 : 1);
}
}
맵리듀스를 실행하면 리듀스는 0%로 동작되지 않는다.
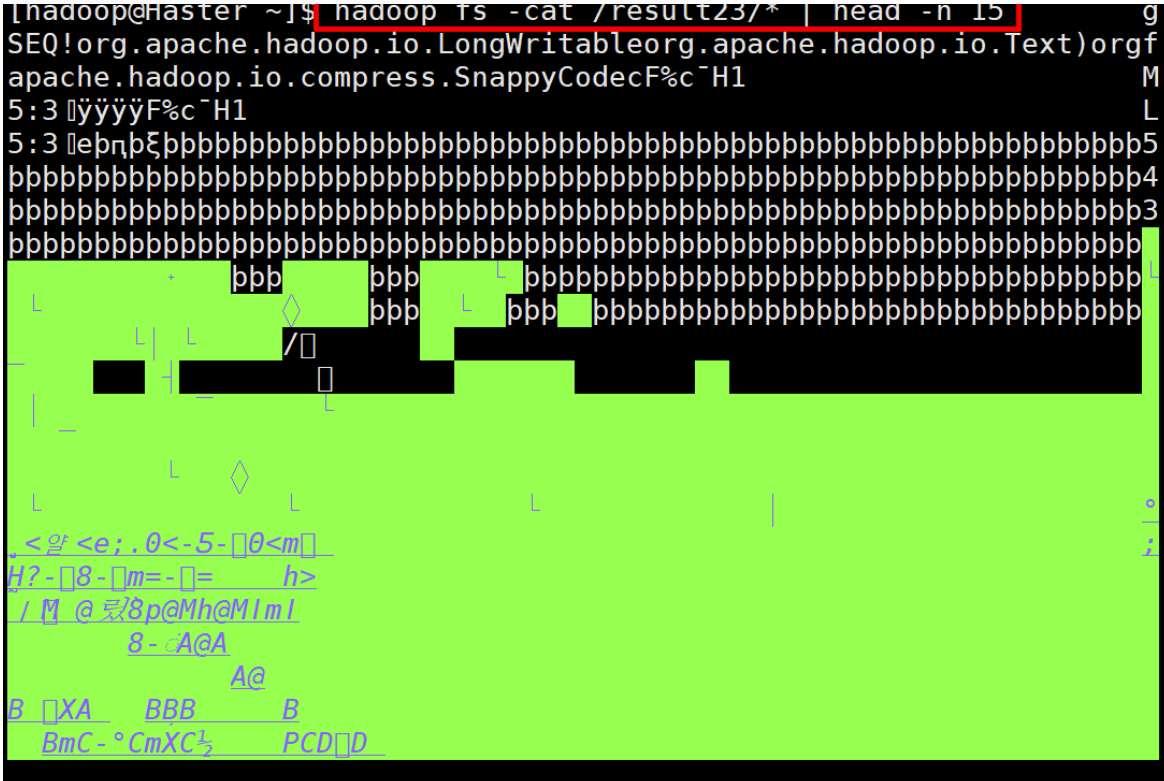
결과를 확인해 보면 압축된 파일로 내용을 전혀 읽을수가 없게 되어 있다.
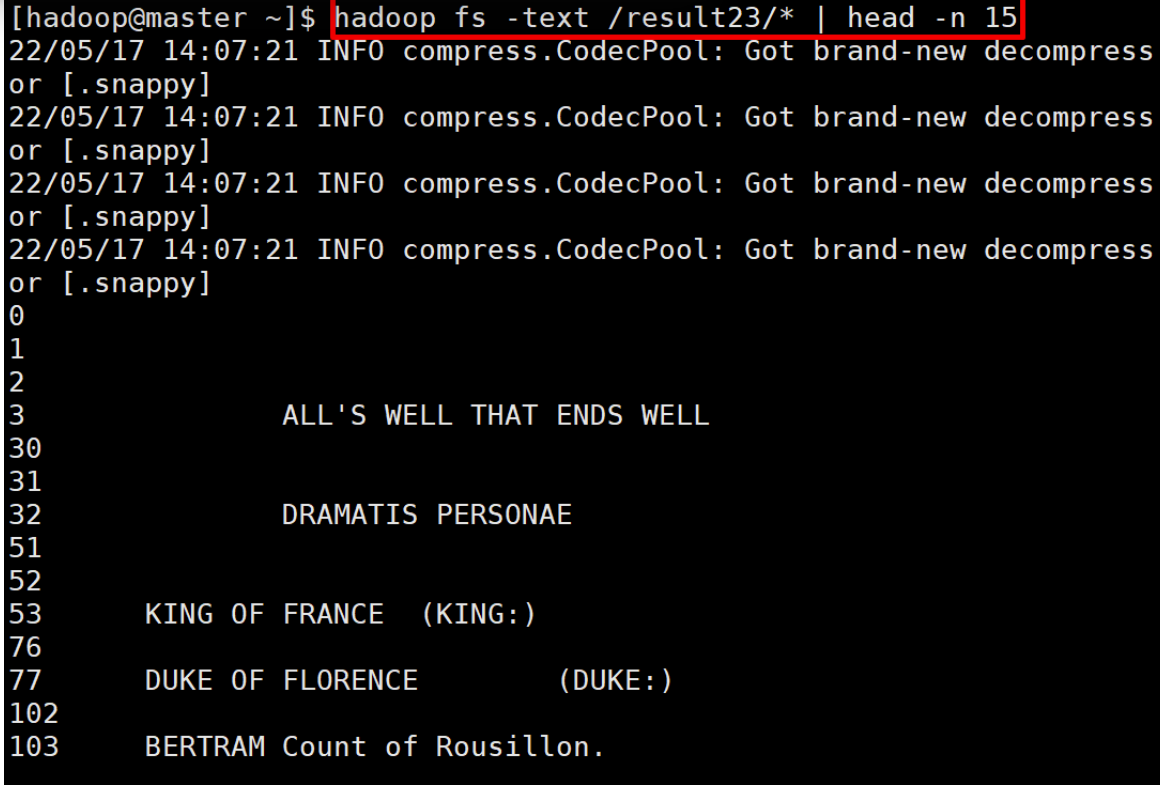
Text 명령어로 압축 파일을 읽어보면 내용이 있는 것을 확인할 수 있다.
반응형
'Data Base > Hadoop' 카테고리의 다른 글
| [Hadoop] : Hive 다운로드 및 환경 변수 설정 (0) | 2022.05.24 |
|---|---|
| [Hadoop] : 하둡 시퀀스 파일 압축 풀기 (0) | 2022.05.24 |
| [Hadoop] : 시퀀스 파일별로 단어별 빈도수 세기 (0) | 2022.05.19 |
| [Hadoop] : SequenceFile 프로그래밍 (0) | 2022.05.17 |
| [Hadoop] : Map 프로그래밍 (0) | 2022.05.17 |




댓글