반응형
맵 프로그래밍은 맵리듀스에서 리듀스를 사용하지 않고 맵만 사용할 때 사용되는 프로그래밍 방식이다.
이미지 프로세싱, 파일 포멧 변경, 분석 대상 샘플링, ETL(Extract, Transform, Load) : 추출, 변환, 로드(저장) 등에 사용한다.
맵 프로그래밍은 리듀서를 사용하지 않기 때문에 생성되는 리듀서 객체는 존재하지 않는다.
맵리듀스의 카운터를 이용한다.
카운터는 맵리듀스에 정보 표현을 위해 사용하는 객체이다.
package hadoop.MapReduce.maponly;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class ImageCount extends Configuration implements Tool {
public static void main(String[] args) throws Exception {
if (args.length != 1) {
System.exit(-1);
}
int exitCode = ToolRunner.run(new ImageCount(), args);
System.exit(exitCode);
}
@Override
public void setConf(Configuration conf) {
// App 이름 정의
conf.set("AppName", "ToolRunner Test");
}
@Override
public Configuration getConf() {
//맵리듀스 전체에 적용될 변수를 정의할 때 사용
Configuration conf = new Configuration();
//변수 정의
this.setConf(conf);
return conf;
}
@Override
public int run(String[] args) throws Exception {
// 캐시 메모리에 올릴 분석 파일
String analysisFile = "/access_log";
Configuration conf = this.getConf();
String appName = conf.get("AppName");
System.out.println("appName = " + appName);
// 맵리듀스 시랳ㅇ을 위한 잡 객체를 가져온다.
// 하둡이 실행되면, 기본적으로 잡 객체를 메모리에 올린다.
Job job = Job.getInstance(conf);
// 호출이 발생하면, 메모리에 저장하여 캐시 처리 수행
// 하둡 분선 파일 시스테에 저장된 파일만 가능함
job.addCacheFile(new Path(analysisFile).toUri());
// 맵리듀스 잡이 시작되는 main 함수가 존재하는 파일 설정
job.setJarByClass(ImageCount.class);
// 맵리듀스 잡 이름 설정, 리소스 매니저 등 맵리듀스 실행 결과 및 로그 확인할 때 편리
job.setJobName(appName);
// 분석할 폴더(파일) -- 첫 번째 파라미터
FileInputFormat.setInputPaths(job, new Path(analysisFile));
// 분석 결과가 저장되는 폴더(파일) -- 두 번째 파라미터
FileOutputFormat.setOutputPath(job, new Path(args[0]));
// 맵리듀스의 맵 역할을 수행하는 Mapper 자바 파일 설정
job.setMapperClass(ImageCountMapper.class);
// 리듀서 객체를 생성하지 못 하도록 객체의 수를 0 으로 정의
job.setNumReduceTasks(0);
// 맵리듀스 실행
boolean success = job.waitForCompletion(true);
if (success) {
//맵리듀스의 Counter는 맵리듀스 실행 결과에 대한 보고를 위해 활용하는 영역
// 맵 분석 결과에 대한 결과를 Counter 영역에 저장
// jpg를 요청한 URL 수
long jpg = job.getCounters().findCounter("imageCount", "jpg").getValue();
// gif를 요청한 URL 수
long gif = job.getCounters().findCounter("imageCount", "gif").getValue();
//jpg와 gif를 제외한 요청한 URL 수
long other = job.getCounters().findCounter("imageCount", "other").getValue();
return 0;
} else {
return 1;
}
}
}
- ImageCount
package hadoop.MapReduce.maponly;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class ImageCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] fields = value.toString().split("\\"");
if (fields.length > 1) {
String request = fields[1];
fields = request.split(" ");
if (fields.length > 1) {
String fileName = fields[1].toLowerCase();
if (fileName.endsWith(".jpg")) {
context.getCounter("imageCount", "jpg").increment(1);
} else if (fileName.endsWith(".gif")) {
context.getCounter("imageCount", "gif").increment(1);
} else {
context.getCounter("imageCount", "other").increment(1);
}
}
}
}
}
- ImageCountMapper
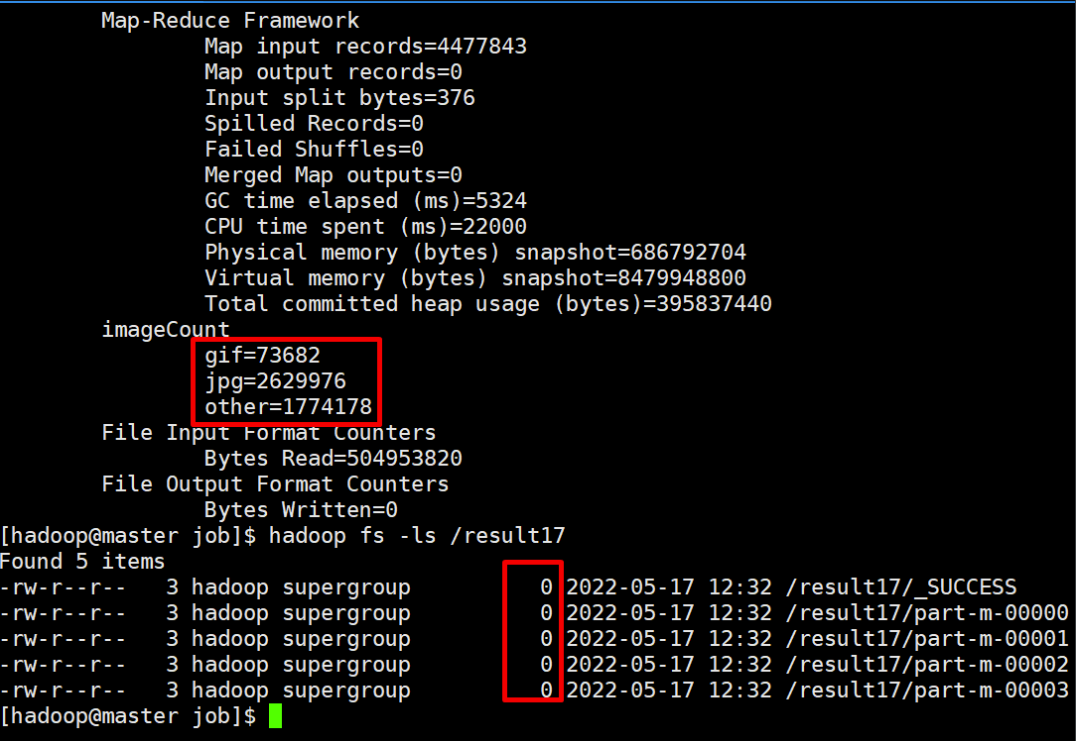
아직 결과 값을 넣어둔 게 없어서 용량은 0으로 나온다.
반응형
'Data Base > Hadoop' 카테고리의 다른 글
| [Hadoop] : 시퀀스 파일별로 단어별 빈도수 세기 (0) | 2022.05.19 |
|---|---|
| [Hadoop] : SequenceFile 프로그래밍 (0) | 2022.05.17 |
| [Hadoop] : Combiner, 컴바이너 (0) | 2022.05.10 |
| [Hadoop] : URL 전송 결과가 성공인 요청 분석하기 (0) | 2022.05.03 |
| [Hadoop] : 맵리듀스 제어 함수, setup, cleanup (0) | 2022.05.03 |


댓글