데이터프레임 다루기
벡터
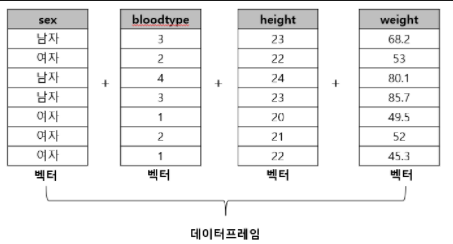
R의 최소 데이터 단위이다.

여러 개의 벡터가 모여 하나의 데이터 프레임을 이루게 된다.
R에서의 4가지 벡터
character : 문자열을 나타낸다.
factor : 순서형 변수와 명목형 변수를 모두 나타낸다. 카테고리형 변수를 표현하는 데이터 타입이다.
integer : 정수 값을 표현하는 데이터 타입이다. 이산형 변수에서 사용한다.
numeric : 연속형 변수는 이 numeric 타입을 사용하는 것을 권장하고, 실수까지 표현이 가능한 데이터 타입이다.
벡터 만들기
a1 <- c(5,3,6,3,1)
a1
c()함수는 벡터를 만드는 함수이다.
괄호 안에 데이터를 넣으면 벡터가 된다.
is(a1)
벡터의 종류를 확인하기 위해 is() 함수를 사용한다. 확인해 보면 Integer인 줄 알았지만 numeric이다. R은 더 정확하게 알려주지 않으면 더 큰 개념으로 정의하게 된다.
a1 <- c(1L,2L,3L)
is(al)
숫자 뒤에 L을 붙이게 되면 numeric이 아니라 integer가 된다.
a1 <- as.integer(a1)
is(a1)
변환도 가능하다.
b <- c(1.23, 6.63452, 4.34231)
b
is(b)
연속형 변수는 그냥 실수 값을 넣으면 된다.
a2 <- c("짬뽕", "짜장", "짬뽕", "짜장면")
a2
c() 함수를 사용했다. 따옴표가 데이터를 감싸면 문자열 벡터를 만들 수 있다.
a3 <- c(7,3,5,7,2,"짜장면")
a3
is(a3)
Integer를 입력하다 마지막만 character을 입력했지만 모두 character가 되었다. 벡터는 여러 종류가 섞이지 않고 한 가지 종류만 선택한다.
a2 <- as.factor(a2)
a2
is(a2)
Levels가 보이는데 명목형 변수의 종류를 여기에 표시를 해두는 것이다.
명목형 변수는 통계학에서 계산을 목적으로 바꿔서 사용하기도 한다. 그래서 factor로 변환하면 이 객체 안에는 이미 integer가 들어가 있게 된다.
a2 <- factor(a2, ordered=T)
a2
Levels를 보면 < 표시가 추가된 것을 확인할 수 있는데 순서를 나타내는 것이다. (순서형 변수 만들기)
이번에는 여러 개의 벡터를 만들어 데이터 프레임을 만들어 본다.
a1 <- c(5,3)
a1
벡터를 만든다.
a2 <- c("짬뽕", "짜장")
a2
문자열 벡터를 만든다.
a3 <- c(3.132, 4.234)
a3
연속형 변수를 벡터로 만든다.
DF <- data.frame(a1,a2,a3)
DF
만든 벡터들로 데이터 프레임을 만든다. 데이터 프레임을 만들기 위해 data.frame()함수를 사용한다. 데이터 프레임에 들어갈 벡터의 길이(원소 개수가)가 밭드시 같아야 한다.
DF <- data.frame(count=a1, food=a2,meanCount=a3)
DF
벡터의 이름을 정해준다. data.frame에 벡터를 넣을 때 이름을 넣어주면 원하는 변수명을 만들 수 있다.
이번에는 외부 데이터를 가져오는 것과 변수를 선택해 본다.
DF <- read.csv("example_studentlist.csv")
데이터 파일을 불러온다. 외부에서 테이블로 정리된 데이터를 가져오면 R에서는 data.frame 객체에 저장되게 된다.
is.vector(DF$height)
변수가 벡터인지 확인한다.
str(DF)
데이터프레임 구조 파악하기, 17개 관측치가 있고 8개의 변수 있다고 알려주고 변수들이 어떤 데이터형인지 무슨 값인지 요약해준다.
DF$height
데이터 프레임 객체에 $를 붙이고 불러오고 싶은 변수의 이름을 적어주면 된다. 이렇게 선택한 벡터는 바로 함수에 넣어 사용할 수 있다.
mean(DF$height)
평균을 구하는 함수이다.
Height <- DF$height
Height
다른 객체에 저장도 할 수 있다.
DF[[7]]
Height 변수가 7번째 열에 있으니 위와 같이 적을 수 있다. 특이 점은 []가 두개인 점인데 [[]]를 사용하면서 한 단계 더 들어가 값 자체를 가져오게 된다.
이번에는 여러 개 변수를 선택해 본다.
DF <- read.csv("example_studentlist.csv")
예제 데이터 파일을 불러온다.
DF[c(6,7)]
위치 값으로 여러 개 변수 를 선택한다.
여러 개를 선택할 때 c() 함수를 사용해야 한다.
DF[c("bloodtype", "height")]
변수명으로 여러 개 변수를 선택한다.
DF[,7]
행렬 방식으로 변수를 선택한다. 콤마를 기준으로 앞을 생략하고 뒤에만 번호를 넣으면 7번째 열만 선택하게 된다.
DF[2,]
뒤를 생략하고 앞을 적으면 행이 선택된다.
DF[2,1]
앞, 뒤 모두 적으면 변수값 혹은 관측값이 나오게 된다.
DF[,"height"]
행렬 방식이면서 변수명으로 선택한다.
이번에는 쉽게 변수를 선택하는 방법이다.
Df <- read.csv("example_studentlist.csv")
매번 DF$height 이렇게 변수를 선택할 때 마다 데이터 프레임 이름을 적는 것이 귀찮을 수 있다. R에는 검색 목록이 있다. 이곳에 등록하면 height 변수로 바로 접근이 가능하다. 먼저 예제 파일을 불러왔다.
attach(DF)
검색 목록에 데이터프레임을 올린다.
height
변수를 선택한다. DF$height라고 하지 않고 height라고 해도 변수로 접근이 가능하다.
detach(DF)
검색 목록에 올린 객체를 삭제한다.
이번에는 조건으로 변수를 선택한다.
DF <- read.csv("example_studentlist.csv")
데이터프레임에서 키가 170보다 큰 사람을 선택할 수 있다. subset()함수를 사용한다. 먼저, 예제 데이터 파일을 불러온다.
subset(DF, subset=(height>170))
키가 170보다 큰 관측치를 선택한다.
subset(DF, select=c(name,height),subset=(height>180))
키가 180 이상인 사람의 이름과 키만 볼 수 다. select 인자를 이용하면 관측치의 원하는 변수만 볼 수 있다.
subset(DF, select=-height)
특정 변수만 빼고 볼 수 있다.
subset(DF, select=c(-height, -weight))
여러 개도 가능하다.
'프로그래밍언어 > R' 카테고리의 다른 글
| [R] : 데이터 프레임 다루기(3) (0) | 2022.03.14 |
|---|---|
| [R] : 데이터 프레임 다루기(2) (0) | 2022.03.14 |
| [R] : 표로 데이터 정리하기 (0) | 2022.03.11 |
| [R] : R에서 외부 데이터 읽어 들이는 다양한 방법 (0) | 2022.03.02 |
| [R] : 패키지, Package (0) | 2022.03.02 |


댓글