자연어처리?
- 내가 말 하고 있는 단어, 타이핑하는 글 등을 컴퓨터가 인식할 수 있게 하는 걸 자연어처리라고 합니다.
- 자연어처리는 한국어로 사용하기엔 어렵습니다.
- 한국어 문장을 입력받아 한국어 어휘 형태 및 의미 와 문장의 구조 및 의미를 분석하여 언어를 이해하는 기술입니다.
- 형태소 분석은 언어 분석 기술 중 하나로 문장을 분해가능한 의미 최소단위로 분리하고 품사를 태깅합니다.
- 형태소 분석과 명사 분석은 가장 보편적으로 많이 사용된 분석 기술입니다.
- 언어 분석은 반드시 데이터사전이 필요하며, 데이터사전은 꾸준히 학습시켜야 합니다.
- 자연어처리는 주로 영어로 되어 있는데 영문학적으로 구조가 명확히 분류되어 있어서 (형태가 명확 1형식, 2형식, 품사가 명확하다. 띄어쓰기가 정확하다.) 자연어처리하기에 좋은 환경입니다.
- 반면에 한국어는 조사가 너무 많이 있고, 신조어도 많이 나오고 규칙이 명확하지 않기 때문에 외국에서 만든 기술로 한국어를 적용시킬 수 없다는 문제가 있습니다.
- 이런 문제를 놔두고 한국어에도 적용시키기 위해 사용하는 것이 형태소분석입니다.
- Komoran은 자바에서 사용하는 형태소 분석기입니다.

pom.xml
<repository>
<id>jitpack.id</id>
<url>https://jitpack.io</url>
</repository>오라클에서 메이븐 저장소에 제공을 하고 있지 않기 때문에, 메이븐 사설 저장소 사용합니다.
<repositories> 안에 넣어줍니다.
<dependency>
<groupId>com.github.shin285</groupId>
<artifactId>KOMORAN</artifactId>
<version>3.3.4</version>
</dependency>자연어 처리 - 형태소 분석기 (Komoran 다운로드를 위한 레파지토리 등록합니다.
<dependency>안에 넣어줍니다.
package poly.service;
import java.util.List;
import java.util.Map;
public interface IWordAnalysisService {
//자연어 처리 - 형태소 분석 (명사만 추출하기)
List<String> doWordNouns(String text) throws Exception;
//빈도수 분석(단어별 출현 빈도수)
Map<String, Integer> doWordCount(List<String> pList) throws Exception;
//분석할 문장의 자연어 처리 및 빈도수 분석 수행
Map<String, Integer> doWordAnalysis(String text) throws Exception;
}IWordAnalysisService
package poly.service.impl;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Iterator;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.HashSet;
import org.apache.log4j.Logger;
import org.springframework.stereotype.Service;
import kr.co.shineware.nlp.komoran.constant.DEFAULT_MODEL;
import kr.co.shineware.nlp.komoran.core.Komoran;
import kr.co.shineware.nlp.komoran.model.KomoranResult;
import poly.service.IWordAnalysisService;
import poly.util.CmmUtil;
@Service("WordAnalysisService")
public class WordAnalysisService implements IWordAnalysisService {
private Logger log = Logger.getLogger(this.getClass());
//자연어 처리 - 형태소 분석기인 Komoran를 메모리에 올리기 위해 WordAnalysisService 클래스 내 전역 변수로 설정합니다.
Komoran nlp = null;
//생성자 사용함 - 톰켓에서 부팅할 때 @Service를 모두 메모리에 올립니다.
//톰켓이 메모리에 올릴 때, 생성자에 선언한 Komoran도 같이 메모리에 올라가도록 생성자에 코딩합니다.
//생성자에서 Komoran을 메모리에 올리면, 매번 메모리에 올려서 호출하는 것이 아니라,
// 메모리에 올리간 객체만 불러와서 사용할 수 있기 때문에 처리 속도가 빠릅니다.
public WordAnalysisService() {
log.info(this.getClass().getName() + ".WordAnalysisService creator Start !");
//NLP 분석 객체 메모리 로딩합니다.
this.nlp = new Komoran(DEFAULT_MODEL.LIGHT); // 학습데이터 경량화 버전( 웹 서비스에 적합합니다. )
//this.nlp = new Komoran(DEFAULT_MODEL.FULL); // 학습데이터 전체 버전(일괄처리 : 배치 서비스에 적합합니다.)
log.info("난 톰켓이 부팅되면서 스프링 프렝미워크가 자동 실행되었고, 스프링 실행될 때 nlp 변수에 Komoran 객체를 생성하여 저장하였다.");
log.info(this.getClass().getName() + ".WordAnalysisService creator End !");
}
@Override
public List<String> doWordNouns(String text) throws Exception {
log.info(this.getClass().getName() + ".doWordAnalysis Start !");
log.info("분석할 문장 : " + text);
//분석할 문장에 대해 정제(쓸데없는 특수문자 제거)
String replace_text = text.replace("[^가-힣a-zA-Z0-9", " ");
log.info("한국어, 영어, 숫자 제외 단어 모두 한 칸으로 변환시킨 문장 : " + replace_text);
//분석할 문장의 앞, 뒤에 존재할 수 있는 필요없는 공백 제거
String trim_text = replace_text.trim();
log.info("분석할 문장 앞, 뒤에 존재할 수 있는 필요 없는 공백 제거 : " + trim_text);
//형태소 분석 시작
KomoranResult analyzeResultList = this.nlp.analyze(trim_text);
//형태소 분석 결과 중 명삼나 가져오기
List<String> rList = analyzeResultList.getNouns();
if (rList == null) {
rList = new ArrayList<String>();
}
//분석 결과 확인을 위한 로그 찍기
Iterator<String> it = rList.iterator();
while (it.hasNext()) {
//추출된 명서
String word = CmmUtil.nvl(it.next());
log.info("word : " + word);
}
log.info(this.getClass().getName() + ".doWordAnalysis End !");
return rList;
}
@Override
public Map<String, Integer> doWordCount(List<String> pList) throws Exception {
log.info(this.getClass().getName() + ".doWordCount Start !");
if (pList ==null) {
pList = new ArrayList<String>();
}
//단어 빈도수(사과, 3) 결과를 저장하기 위해 Map객체 생성합니다.
Map<String, Integer> rMap = new HashMap<>();
//List에 존재하는 중복되는 단어들의 중복제거를 위해 set 데이터타입에 데이터를 저장합니다.
//rSet 변수는 중복된 데이터가 저장되지 않기 떄문에 중복되지 않은 단어만 저장하고 나머지는 자동 삭제합니다.
Set<String> rSet = new HashSet<String>(pList);
//중복이 제거된 단어 모음에 빈도수를 구하기 위해 반복문을 사용합니다.
Iterator<String> it = rSet.iterator();
while(it.hasNext()) {
//중복 제거된 단어
String word = CmmUtil.nvl(it.next());
//단어가 중복 저장되어 있는 pList로부터 단어의 빈도수 가져오기
int frequency = Collections.frequency(pList, word);
log.info("word :" + word);
log.info("frequency : " + frequency);
rMap.put(word, frequency);
}
log.info(this.getClass().getName() + ".doWordCount End !");
return rMap;
}
@Override
public Map<String, Integer> doWordAnalysis(String text) throws Exception {
//문장의 명사를 추출하기 위한 형태소 분석 실행
List<String> rList = this.doWordNouns(text);
if(rList == null) {
rList = new ArrayList<String>();
}
//추출된 명사 모음(리스트)의 명사 단어별 빈도수 계산
Map<String, Integer> rMap = this.doWordCount(rList);
if(rMap == null) {
rMap = new HashMap<String, Integer>();
}
return rMap;
}
}WordAnalysisService
주석을 참고하면 됩니다.
package poly.controller;
import java.util.HashMap;
import java.util.Map;
import javax.annotation.Resource;
import org.apache.log4j.Logger;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import poly.service.IWordAnalysisService;
@Controller("WordController")
public class WordController {
private Logger log = Logger.getLogger(this.getClass());
@Resource(name="WordAnalysisService")
private IWordAnalysisService wordAnalysisService;
@RequestMapping(value = "word/analysis")
@ResponseBody
public Map<String, Integer> analysis() throws Exception {
log.info(this.getClass().getName() + ".inputForm !");
//분석할 문장
String text = "아침에 밥을 꼭 먹고 점심엔 점심 밥을 꼭 먹고 저녁엔 저녁 밥을 꼭 먹자!";
//신조어 및 새롭게 생겨난 가수 및 그룹명은 제대로 된 분석이 불가능합니다.
// 새로운 명사 단어들은 어떻게 데이터를 처리해야 할까?? => 데이터사전의 주기적인 업데이트
Map<String, Integer> rMap = wordAnalysisService.doWordAnalysis(text);
if(rMap == null) {
rMap = new HashMap<String, Integer>();
}
return rMap;
}
}WordController
주석을 참고하면 됩니다.

서버를 돌려줍니다.
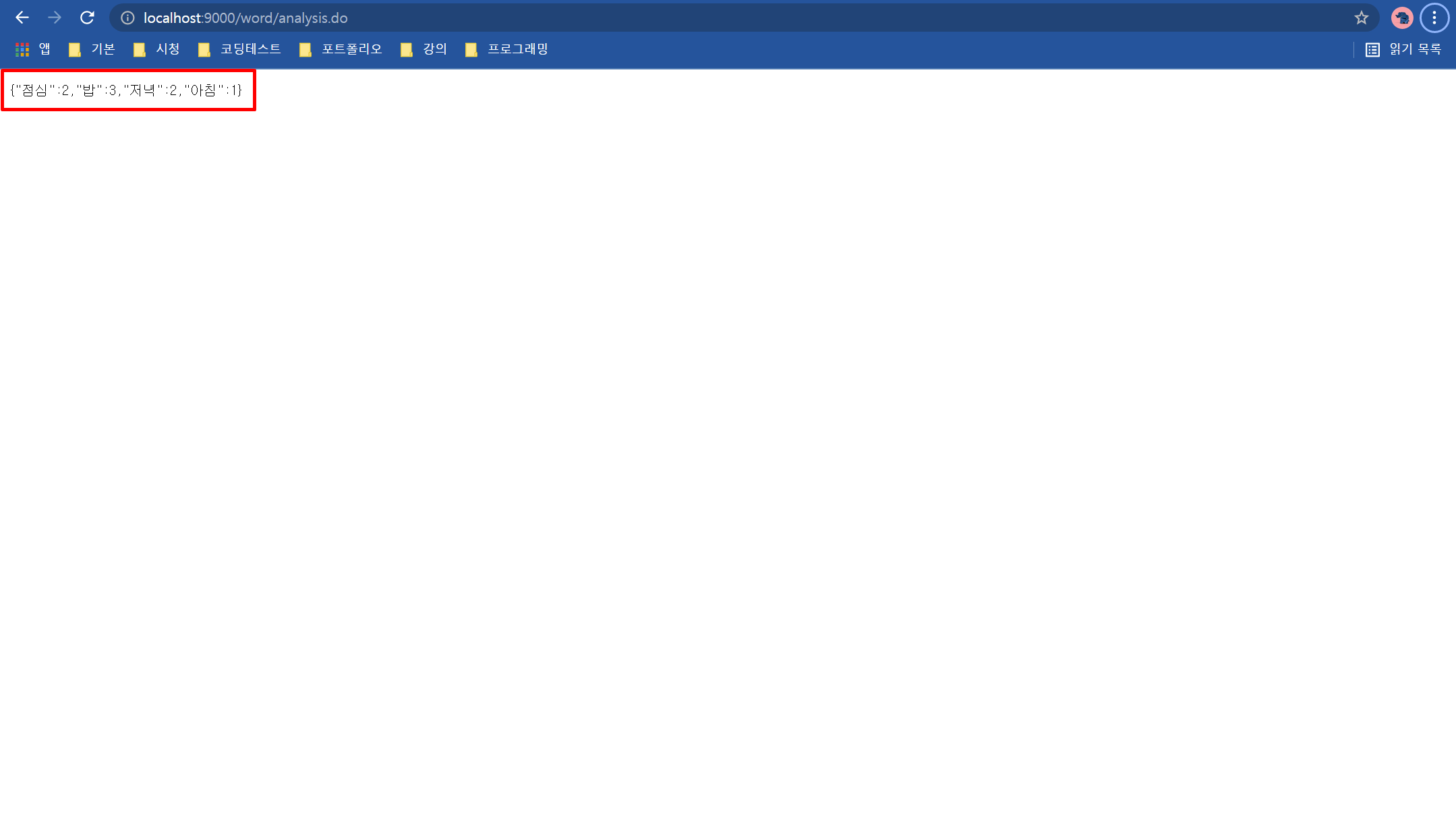
중복 단어 체크와 단어 분석이 완료되었습니다.
특수 문자 역시 제거가 되어 나왔습니다.
'Framework & Library > Spring Framework' 카테고리의 다른 글
| [Spring Framework] : 스프링 프레임워크 자문 자답 16제 (0) | 2021.12.10 |
|---|---|
| [Spring Framework] : 웹 크롤링 후 자연어 처리 (0) | 2021.11.20 |
| [Spring Framework] : Rest 기반 Open API Server 구현 (3부) (0) | 2021.11.03 |
| [Spring Framework] : Rest 기반 Open API Server 구현 (2부) (0) | 2021.11.03 |
| [Spring Framework] : Rest 기반 Open API Server 구현 (1부) (0) | 2021.11.03 |



댓글